Już 26 lipca w Krakowie spotkają się pielgrzymi z całego świata. Uroczystości – również z udziałem Papieża Franciszka – potrwają do 31 lipca br. W tym czasie Polskę, a w szczególności Małopolskę, odwiedzą setki tysięcy osób, udających się na spotkania i pielgrzymki w ramach Światowych Dni Młodzieży. Jak młodzi goście z zagranicy widzą Kraków, Polskę i Polaków? Co najbardziej ich zaskakuje? A co najbardziej im się podoba? Co jest dla nich ważne?

By odpowiedzieć na te pytania, Laboratorium Oprogramowania IBM w Krakowie przeanalizuje posty w mediach społecznościowych, opinie uczestników i przy pomocy oprogramowania analitycznego wyciągnie z tego strumienia danych najważniejsze wnioski. Codziennie, od 26 lipca, zespół analityków IBM będzie podsumowywać informacje płynące z sieci.
Analiza wydźwięku opinii wykorzystuje zaawansowane algorytmy eksploracji danych oraz technologie przetwarzania języka naturalnego. Umożliwia analizę dużych ilości informacji w mediach społecznościowych, aby badać opinię publiczną. Analiza wydźwięku pozwala identyfikować oraz mierzyć pozytywne, negatywne i neutralne opinie udostępniane na forach publicznych takich jak Twitter, Facebook, blogi, tablice ogłoszeń w Internecie oraz w innych mediach społecznościowych. Analiza Światowych Dni Młodzieży (World Youth Days) obejmuje swoim zasięgiem dane z serwisów społecznościowych Twitter oraz Facebook. Więcej informacji dotyczących rozwiązań IBM Business Analytics znajduje się na: www.ibm.com/analytics
Skąd płyną dane?
By przeanalizować informacje na temat Światowych Dni Młodzieży organizowanych w Krakowie, skupiliśmy się na danych dostępnych na Twitterze i Facebooku. Posty będą agregowane przy pomocy udostępnionych przez serwisy społecznościowe publicznych API – zarówno Twitter, jak i Facebook (Graph Api) pozwalają na łatwe przetwarzanie interesujących nas informacji.
Do wyszukiwania i pobierania danych napisaliśmy prostą aplikację node.js z wykorzystaniem platformy IBM Cloud.

Przy użyciu wybranych narzędzi oraz zebranych danych, algorytmy mogą wykonać następujące akcje:
- analizę danych geolokalizacyjnych (skąd piszą osoby zainteresowane Światowymi Dniami Młodzieży, które miejsca i atrakcje Krakowa są najbardziej popularne wśród pielgrzymów)
- analizę tekstu (o czym piszą osoby zainteresowane ŚDM )
- analizę wydźwięku (czy przeważa nastawienie pozytywnie, neutralnie, czy też negatywnie do ŚDM)
- statystykę opisową (jak duże jest zainteresowanie ŚDM, w jakich językach piszą Polacy, które z języków, krajów, miast są najbardziej popularne)
Przykłady:
1. „Word Cloud” w kształcie lajkonika przy użyciu Jupyter Notebook
2. Tweety w różnych językach w czasie, z naniesionymi chmurami wyrażeń przy użyciu SPSS Modeler Plus Jupyter Notebook
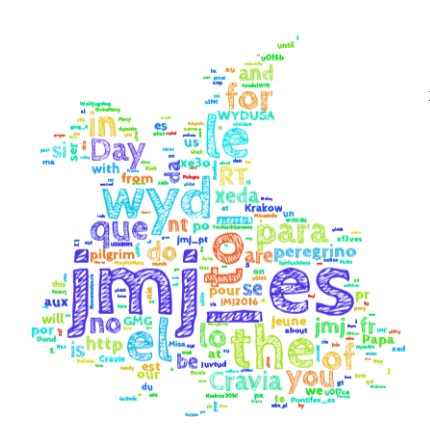
Rysunek 1. „Word Cloud” w kształcie lajkonika przy użyciu Jupyter Notebook. Widać mocną sekcję hiszpańskojęzyczną (#jmj_es = Jornada Mundial de la Juventud), ogólny hashtag #wyd czy pielgrzymów z USA #wydusa
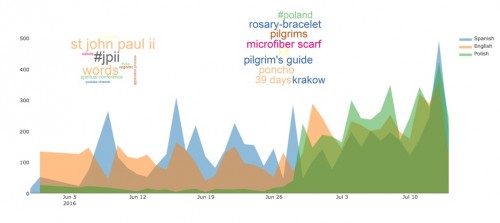
Rysunek 2. Tweets per język w czasie z naniesionymi chmurami wyrażeń przy użyciu SPSS Modeler plus Jupyter Notebook. Dokładnie widać na przykład moment ogłoszenia zawartości pakietu pielgrzyma, widzimy też, że coraz więcej tweetów pojawia się w języku polskim.
Jak to działa – opis techniczny
Dane w oryginalnym formacie (json) po pobraniu z serwisów społecznościowych, są zapisywane w bazie danych Cloudant (NoSQL Cloud DB). W kolejnym kroku dane w formacie json sa konwertowane do relacyjnej bazy danych (SQL) DashDB (Cloud Data Warehouse for Analytics). Zarówno Cloudant jak i DashDB są dostępne na platformie bluemix i łatwo integrowalne z naszą aplikacją. Na tym etapie nasze dane są już dostępne do dalszej analizy.

Platforma Bluemix oraz produkty z grupy IBM SPSS dostarczają nam szeroki zestaw narzędzi do analizy danych. W przypadku analizy danych dotyczących Światowych Dni Młodzieży zdecydowaliśmy się na użycie SPSS Modelera z Text Analytics, Apache Spark z Jupyter Notebooks oraz Node-RED na platformie Bluemix. Zamiast komponentu do analizy wydźwięku (Node-RED), możemy również użyć dedykowanego serwisu Watson Tone Analyzer. Jako język programowania wybraliśmy pythona, zarówno dla Jupyter Notebooks, jak i SPSS Modelera. Dodatkowo skorzystaliśmy z nastepujących bibliotek pythonowych i rozszerzeń do SPSS Modelera:
- biblioteki pythonowe do wizualizacji: seaborn, plotly, wordcloud
- rozszerzenia do SPSS Modelera: googleMaps

Pełny schemat analizy:

źródło: IBM
Kan





Zostaw komentarz